记录一下最近面试遇到的一些问题。
Duboo的默认线程池大小
阅读代码的时候没有注意到这一点,瞎猜了一下是CPU核数的2倍。答案是默认线程池核心线程数是200 。
认真探究了一下,具体参考:如何合理地估算线程池大小
跟小马哥(桃谷)探讨这个问题,他的看法是:
主要是因为如果 RPC 的设置为 处理器个数 x2 或 x4 的话,当并发请求非常高的时候,会出现线程池堵塞,换言之,大量的线程处于等待状态。所以 RPC 的并发数量很大,也就是另可让 CPU 时间片轮替,也不希望堵塞。不同框架的设值也不一定都一样,比如 HSF 就是 700。
Dubbo是一个RPC框架,所以是IO密集型的任务,线程等待时间相对于CPU时间长很多,所以线程数可以设置较高,不过也是支持配置项定义的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class FixedThreadPool implements ThreadPool {
public Executor getExecutor(URL url) {
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
|
如何判断链表相交
面试官问的是判断链表正交,当时一脸懵逼,反问正交是什么意思,结果这个问题就被跳过了。
判断链表正交可以通过将两个链表首尾相连后转为判断链表是否有环的问题。
常用的思路是通过快慢指针来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| public class LoopDetect {
static class Node{
private Integer value;
private Node next;
public Integer getValue() {
return value;
}
public void setValue(Integer value) {
this.value = value;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public Node() {
}
public Node(Integer value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Node node = (Node) o;
return Objects.equals(value, node.value);
}
@Override
public int hashCode() {
return Objects.hash(value);
}
}
public Node detect(Node start) {
Node oriStart = start;
Node fast = start;
Node slow = start;
while(slow.equals(oriStart) || (!fast.equals(slow) && slow.next != null)) {
fast = fast.next.next;
slow = slow.next;
}
if(fast.equals(slow)) {
System.out.println(" loop detected !!!" + fast.getValue());
detectLoopStart(fast, oriStart);
}
return fast;
}
public Node detectLoopStart(Node meet, Node start) {
while(!meet.equals(start)) {
meet = meet.next;
start = start.next;
}
System.out.println("found loop start : " + meet.getValue());
return meet;
}
}
|
如何在垂直分表环境下对某个字段做top
思路分两步,第一是map-reduce的思想,分10个表就开10个线程分别处理,每个线程中使用一个小根堆,小根堆在java里面的一个例子就是TreeMap,底层通过红黑树来实现。
数据过来的时候先判断堆是否满了,没满的话就直接添加到堆中。如果堆满了,与堆顶比较,如果比堆顶小则丢弃,如果比堆顶大就用这个值替换堆顶。
大概的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
| TreeMap<Integer, Integer> treeMap = new TreeMap<>();
for (int i = 0; i < 1000; i++) {
if(treeMap.size() < 10) {
treeMap.put(i, i);
} else {
Integer root = treeMap.firstKey();
if(root < i) {
treeMap.remove(root);
treeMap.put(i, i);
}
}
}
|
当时问我时间复杂度是多少,紧张了一下没好好想,其实最差情况就是 n/10log10 + 100log10 。
主要是考察思路。
还问了关于java异常处理的看法
当时自己对异常的看法没有好好整理过,所以回答的比较粗糙,后来自己认真想了想,主要有几个点:
- 具体明确:比如抛出的异常的信息应该包含可以追溯的详细堆栈,再比如对同一try块定义多个catch块,从而对每种异常分别进行恰当的处理
- 提早抛出:即迅速失败,可以有效避免不必要的对象构造或资源占用,比如文件或网络连接
- 延迟捕获:不要在还无能力处理这个异常的时候就捕获异常,你的程序要么可以从异常中有意义地恢复并继续下去,而不导致更 深入的错误;要么能够为用户提供明确的信息,包括引导他们从错误中恢复过来。如果你的方法无法胜任,那么就不要处理异常,把它留到后面捕获和在恰当的层面处理
mysql多栏索引的实现
我只了解过单栏索引是通过B+树来实现的,猜测多栏索引也是通过B+树来做的,也没引发面试官后续可能的问题,有点遗憾。
网上搜到的多栏索引的资料比较少,稍微列举一下:
『浅入浅出』MySQL 和 InnoDB
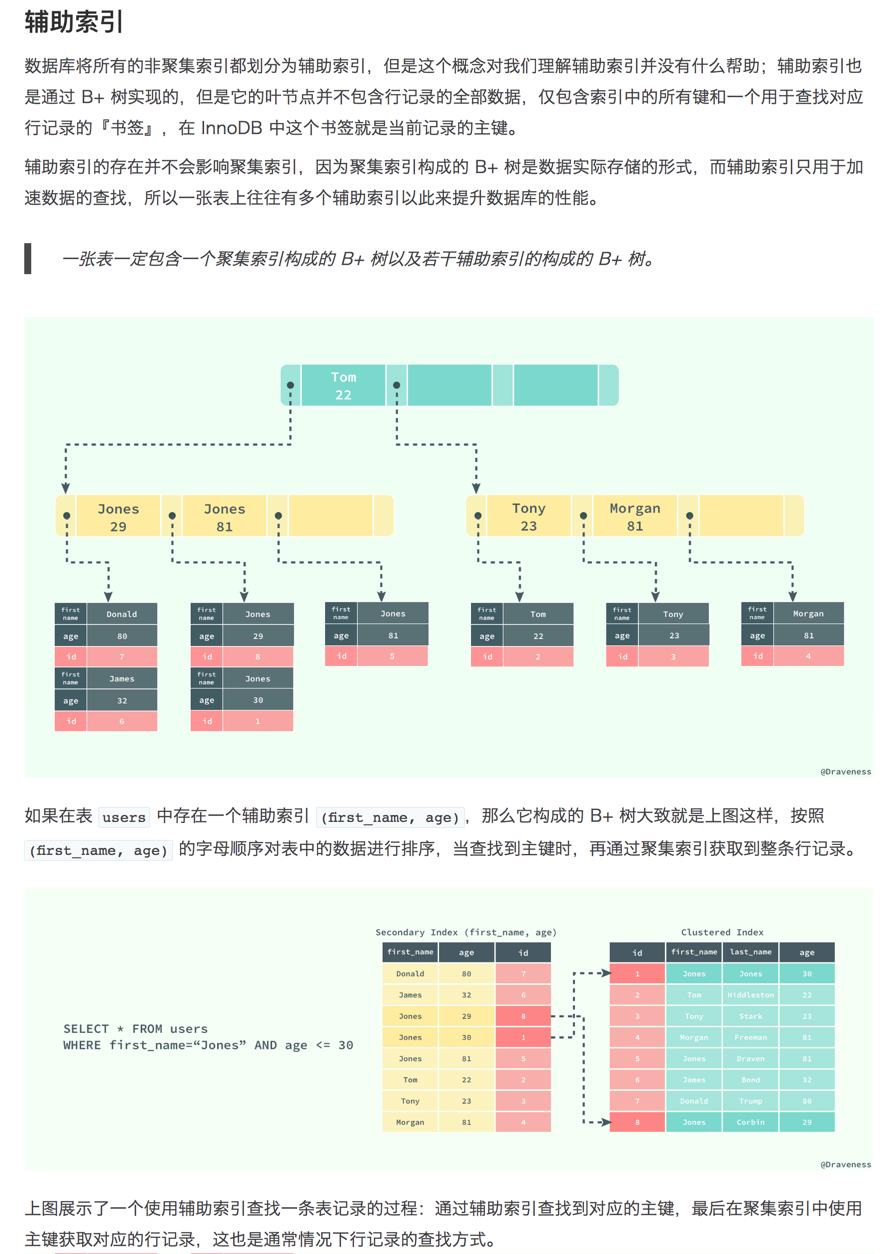
mysql索引最左匹配原则的理解?

关于分布式应用数据库记录锁竞争的问题
我回答的思路是根据场景来选择,如果大概率有竞争,可以通过select ... for update来加锁,如果小概率有竞争,可以通过添加乐观锁字段。面试官追问能否在不用redis等外部依赖的情况跨jvm实现,我回答不可以。希望大家有想法的可以指点一下。
目前大致就是这些,其他一些常规的问题就没有记录了。